
Test Planner
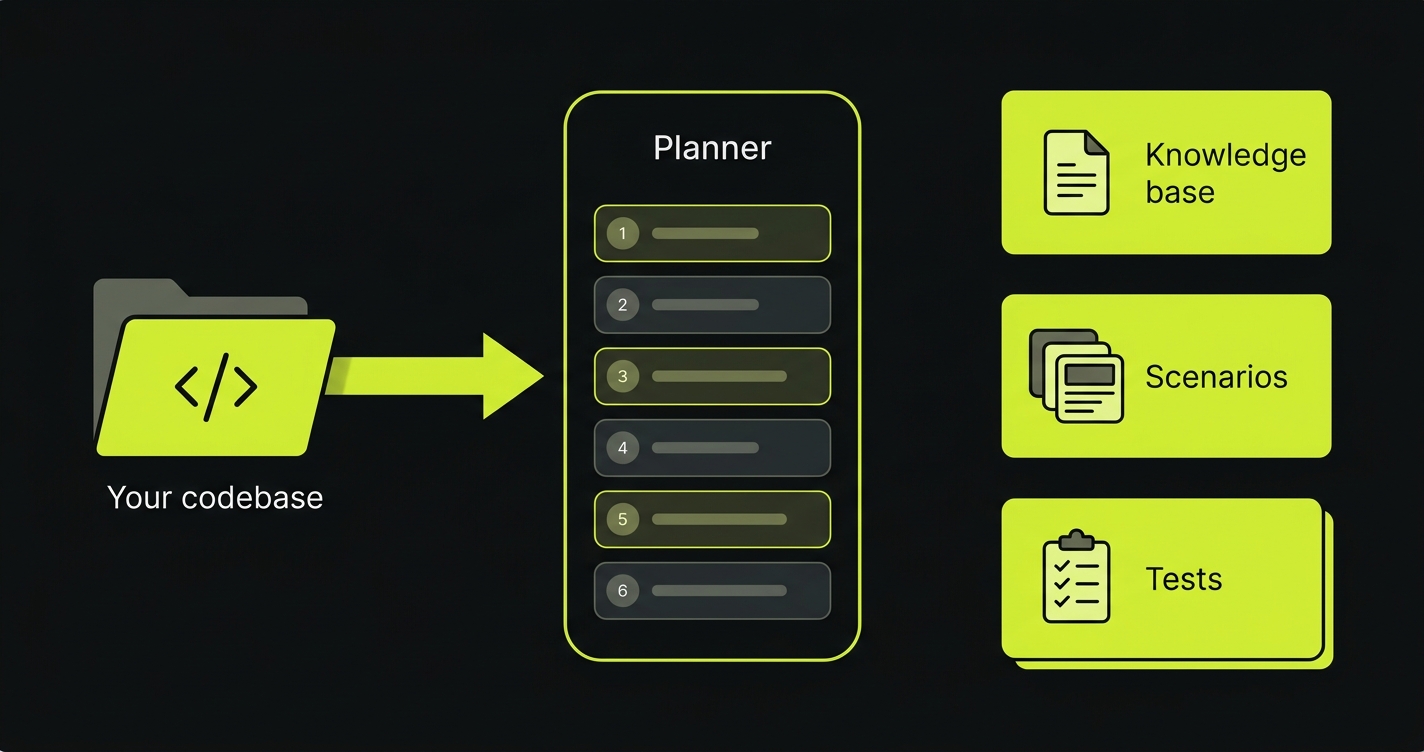
The planner is a command-line tool that reads your codebase and generates a complete end-to-end test suite: the pages and flows to cover, the data each test needs, and the helpers that create and clean up that data. One command, and it runs on managed Autonoma credits - no LLM API key required.
Run it
You launch the planner from the Finish setup → Upload test artifacts step in the dashboard, which hands you a ready-to-paste command with your token and generation id baked in:
AUTONOMA_API_TOKEN=... AUTONOMA_GENERATION_ID=... npx @autonoma-ai/planner@latestThat npx line downloads and runs the planner, published on npm as @autonoma-ai/planner (the installed command is autonoma-planner). Run it from the root of the repo you want to test. It works against your frontend (to map pages and flows) and your backend (to map data models and wire up test data). If those live in separate repos, run it where it can reach both.
Before the run starts, the planner asks a few quick questions to steer the output:
- What is this project?
- Why do you want E2E tests?
- What are the most critical flows?
Then it works through six steps, pausing for your review between each.
What it does
| # | Step | What it does | Output |
|---|---|---|---|
| 1 | Find your pages | Maps every page and route in your app. | - |
| 2 | Build a knowledge base | Learns your features, flows, and UI patterns. | AUTONOMA.md |
| 3 | Map your data models | Finds what your app stores and how each record is created. | entity-audit.md |
| 4 | Design test scenarios | Decides the realistic data each test runs against. | scenarios.md |
| 5 | Set up test data | Wires small helpers that create and clean up that data, validates the full up/down cycle against your app, and submits the recipe. | recipe.json |
| 6 | Generate the tests | Writes the E2E tests as natural-language markdown, covering every page and feature. | qa-tests/ |
Step 5 is where the planner connects to the Environment Factory - it wires the create/teardown helpers and proves they work end to end before any tests are written.
Review checkpoints
The planner pauses after each step and shows you what it produced. Review it before moving on - these checkpoints determine the quality of the final suite. If a step got something wrong, you can retry it with a note steering the agent in the right direction.
The steps that matter most to review:
- Find your pages / Knowledge base - sets what gets tested and how coverage is prioritized.
- Map your data models - decides which models run your real business logic during tests.
- Design test scenarios - fixed values become assertions; variable values become tokens substituted at run time.
- Set up test data - confirms the scenarios actually work against your real database.
Commands and flags
autonoma-planner # run the pipeline (default command)autonoma-planner status # show progress for the current project
# Useful flags--project <path> # target a repo other than the current directory--step <name> # run or re-run a single step--resume # continue from where a previous run stopped--non-interactive # run without the review pauses (CI)--model <id> # pick a different Autonoma-hosted model (still no key needed)Output
Artifacts are written to ~/.autonoma/<project-slug>/ as they're produced. When you run the planner from the dashboard's Finish setup flow, the knowledge base, scenarios, recipe, and generated tests are uploaded to Autonoma automatically at the end - ready to run against your preview environments.